
Spam-Comments-Detection
Started: 2026-02-20
About this project
Spam Comments Detection – Machine Learning Project
Author: Leon Motaung
Technologies Used: Python, Pandas, NumPy, Scikit-learn, CountVectorizer, Naive Bayes, Random Forest
Objective
The objective of this project is to automatically classify YouTube comments as spam or not spam using machine learning techniques. Spam comments often contain promotional links or misleading content intended to redirect users. This system assists content creators and platforms in reducing spam and improving user experience.
Problem Overview
Spam comments detection is a text classification problem in machine learning. Social media platforms such as YouTube rely on automated systems to filter spam comments at scale.
To address this problem, labeled data containing both spam and non-spam comments is required. A publicly available YouTube spam comments dataset from Kaggle was used to train and evaluate the model.
Methodology
- Created a Python virtual environment.
- Installed the required Python libraries.
- Loaded and explored the YouTube spam comments dataset.
- Mapped numeric class labels to descriptive categories.
- Converted text comments into numerical feature vectors using Bag of Words.
- Split the dataset into training and testing sets.
- Trained multiple classifiers and combined them using ensemble learning.
Machine Learning Approach
Text data was transformed using the CountVectorizer technique, which converts text into numerical word-frequency vectors. Two classification models were trained:
- Bernoulli Naive Bayes, suitable for binary text features.
- Random Forest Classifier, which captures complex patterns and reduces overfitting.
These models were combined using a Voting Classifier, where the final prediction is determined by majority voting.
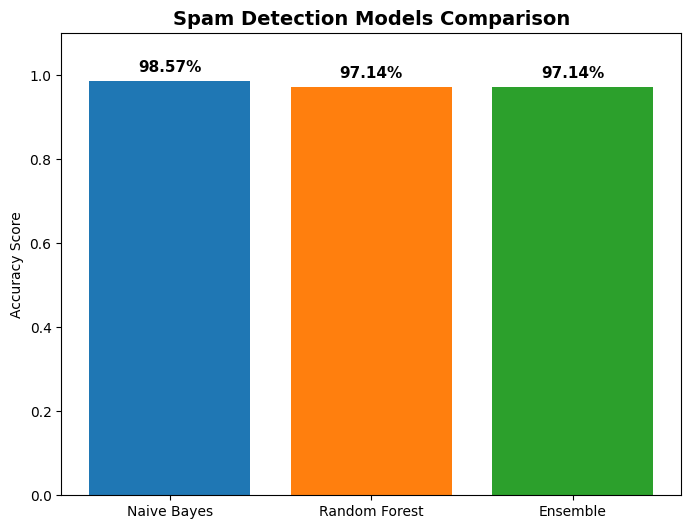
Model Training and Evaluation
The dataset was split into 80% training data and 20% testing data. Model performance was evaluated using accuracy on unseen test samples.
Ensemble Model Accuracy: (dataset dependent)
Model Testing
Spam Comment Example:
"Check this out: https://amanxai.com/" Prediction: Spam Comment
Non-Spam Comment Example:
"Lack of information!" Prediction: Not Spam
Key Learnings
- Text data preprocessing and vectorization techniques.
- Application of ensemble learning for text classification.
- Performance comparison between Naive Bayes and Random Forest models.
- Evaluation of machine learning models using test data.
Insights
Text Requires Numerical Representation
Machine learning models require numerical input, making text vectorization a critical step in natural language processing tasks.
Ensemble Models Improve Stability
Combining multiple classifiers results in more stable and reliable predictions compared to using a single model.
Traditional Models Remain Effective
Classical machine learning models can achieve strong performance in text classification tasks without the need for deep learning.
Project Structure
data/– YouTube spam comments datasetscripts/– Python scripts for training and evaluationmodels/– Trained machine learning modelsREADME.md– Project documentation
This project demonstrates the application of machine learning techniques to a real-world text classification problem using social media data.