
Clustering-Music
Started: 2026-02-23
About this project
Clustering Music Genres – Machine Learning Project
Author: Leon Motaung
Technologies Used: Python, Pandas, NumPy, Scikit-learn, K-Means Clustering, MinMaxScaler, Plotly
Objective
The objective of this project is to group music genres based on similarities in their audio characteristics using unsupervised machine learning. By analyzing patterns in musical features, this system helps identify clusters of songs that share similar sonic properties.
Problem Overview
Music streaming platforms face challenges in recommending songs due to diverse and subjective user preferences. Traditional demographic data alone is insufficient to understand a listener’s taste.
By analyzing the audio characteristics of songs a user listens to, it becomes possible to identify patterns and recommend similar music. This project applies clustering techniques to group songs with comparable musical features.
Dataset Description
The dataset used in this project consists of popular Spotify songs, including metadata such as artist, genre, and year, along with numerical audio features like tempo, energy, loudness, and danceability.
These audio features provide sufficient information to measure similarity between songs.
Methodology
- Loaded the Spotify music dataset using Pandas.
- Removed irrelevant columns such as index values.
- Explored correlations between audio features.
- Selected key numerical audio attributes for clustering.
- Scaled features to a uniform range using Min-Max scaling.
- Applied K-Means clustering to group songs into segments.
- Mapped cluster labels to readable segment names.
Machine Learning Approach
This project uses K-Means clustering, an unsupervised learning algorithm that groups data points based on distance to cluster centroids. Songs with similar audio characteristics are assigned to the same cluster.
The clustering process was performed using selected features such as:
- Beats Per Minute (BPM)
- Loudness
- Liveness
- Valence
- Acousticness
- Speechiness
Model Training and Clustering
The K-Means algorithm was configured to create ten distinct clusters. Each cluster represents a group of songs with similar musical traits.
Number of Clusters: 10 Clustering Type: Unsupervised Learning Algorithm: K-Means
Results
After clustering, a new column named Music Segments was added
to the dataset. Each song was assigned to a cluster representing its
musical similarity group.
Songs from different genres often appeared in the same cluster, indicating that audio characteristics can transcend traditional genre labels.
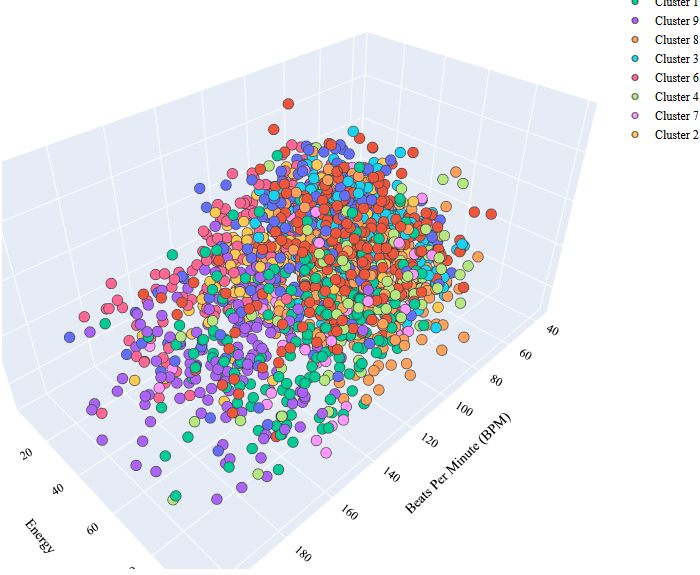
Visualization
A 3D interactive visualization was created using Plotly to explore clusters based on BPM, Energy, and Danceability. This visualization helps in understanding how songs are grouped in feature space.
Key Learnings
- Unsupervised learning can reveal hidden patterns in music data.
- Audio features are powerful indicators of musical similarity.
- K-Means clustering is effective for segmenting large music datasets.
- Data scaling is essential for distance-based algorithms.
Insights
Genres Are Not Absolute
Songs from different genres can share similar audio characteristics, making clustering a valuable alternative to traditional genre classification.
Feature Selection Matters
Choosing the right audio features significantly impacts the quality and interpretability of the clusters.
Clustering Supports Recommendation Systems
Grouping music by similarity enables more personalized and accurate music recommendations for streaming platforms.
Project Structure
data/– Spotify music datasetanalysis/– Data exploration and clustering scriptsvisualization/– Interactive cluster plotsREADME.md– Project documentation
This project demonstrates how clustering techniques can be applied to music data to uncover meaningful patterns and support recommendation systems using machine learning.